
What is Firecrawl
Firecrawl is a powerful web scraping service that turns websites into LLM-ready data. It’s an open-source platform designed to help developers extract clean, structured data from any website, including JavaScript-heavy and protected pages. Firecrawl provides several core capabilities:- Scrape: Extract data from individual web pages in formats like Markdown, JSON, or screenshots
- Crawl: Automatically discover and scrape all pages on a website
- Search: Search the web and get full content from results
- Map: Get a comprehensive view of a website’s structure
Starting with the Right Prompt
The initial prompt you give Mocha is crucial for getting your project started on the right track. When building an app that uses web scraping, you need to be specific about:- What data you want to collect: Clearly describe what information you need from websites
- How the data should be used: Explain how the scraped data fits into your app’s functionality
- Key features: List the main features you want, including any data storage or display requirements
- Technical requirements: Mention any specific services or tools you want to use (like Firecrawl)
- A clear description of the app’s purpose
- Specific features broken down into bullet points
- Technical requirements (Firecrawl)
- Design preferences (clean and simple UI)
Setting up the Firecrawl API Key
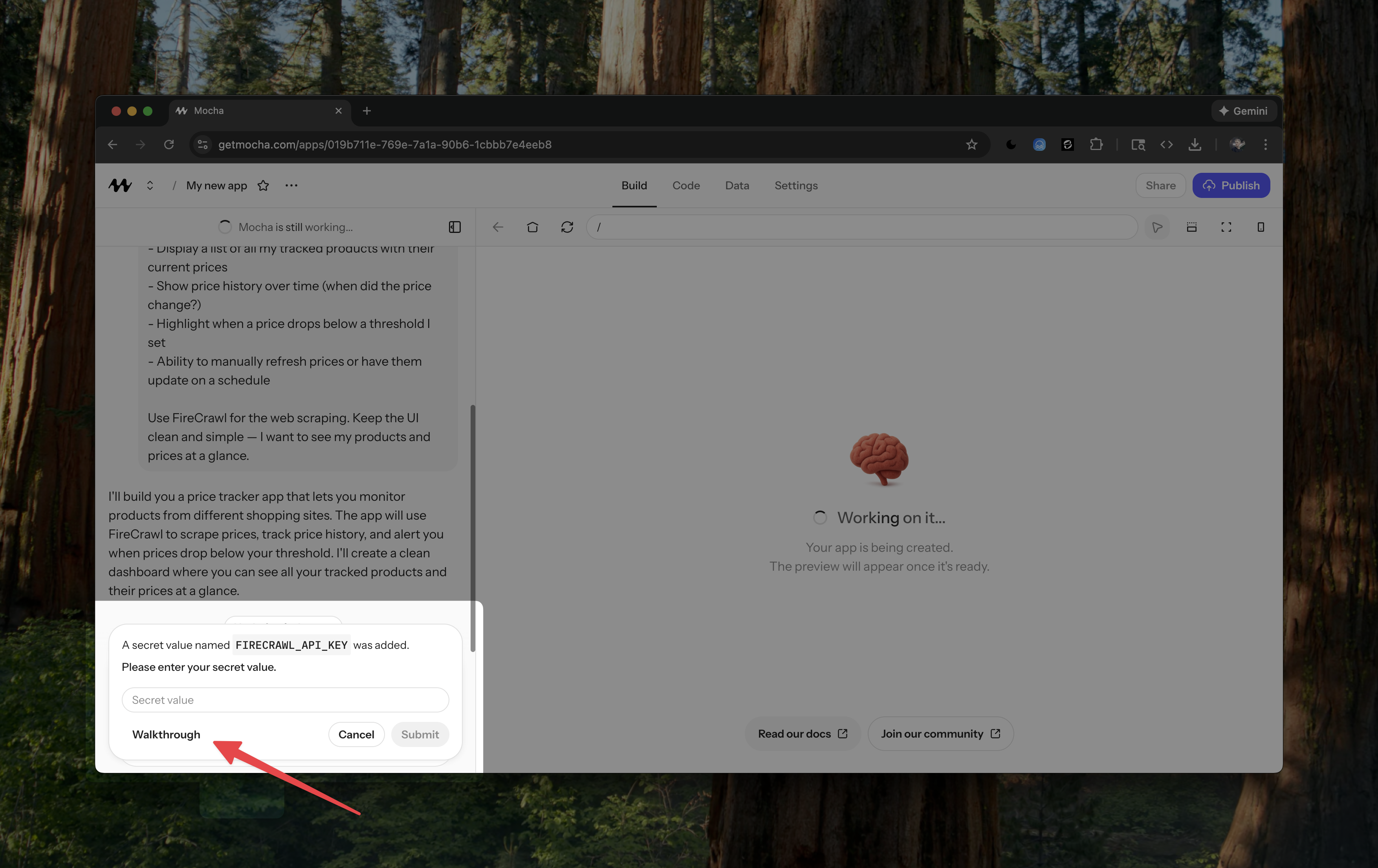
During the build, you should be able to see a prompt to add a secret for the Firecrawl API Key. If you need a walkthrough for how to add this key, click the walkthrough button and follow the instructions.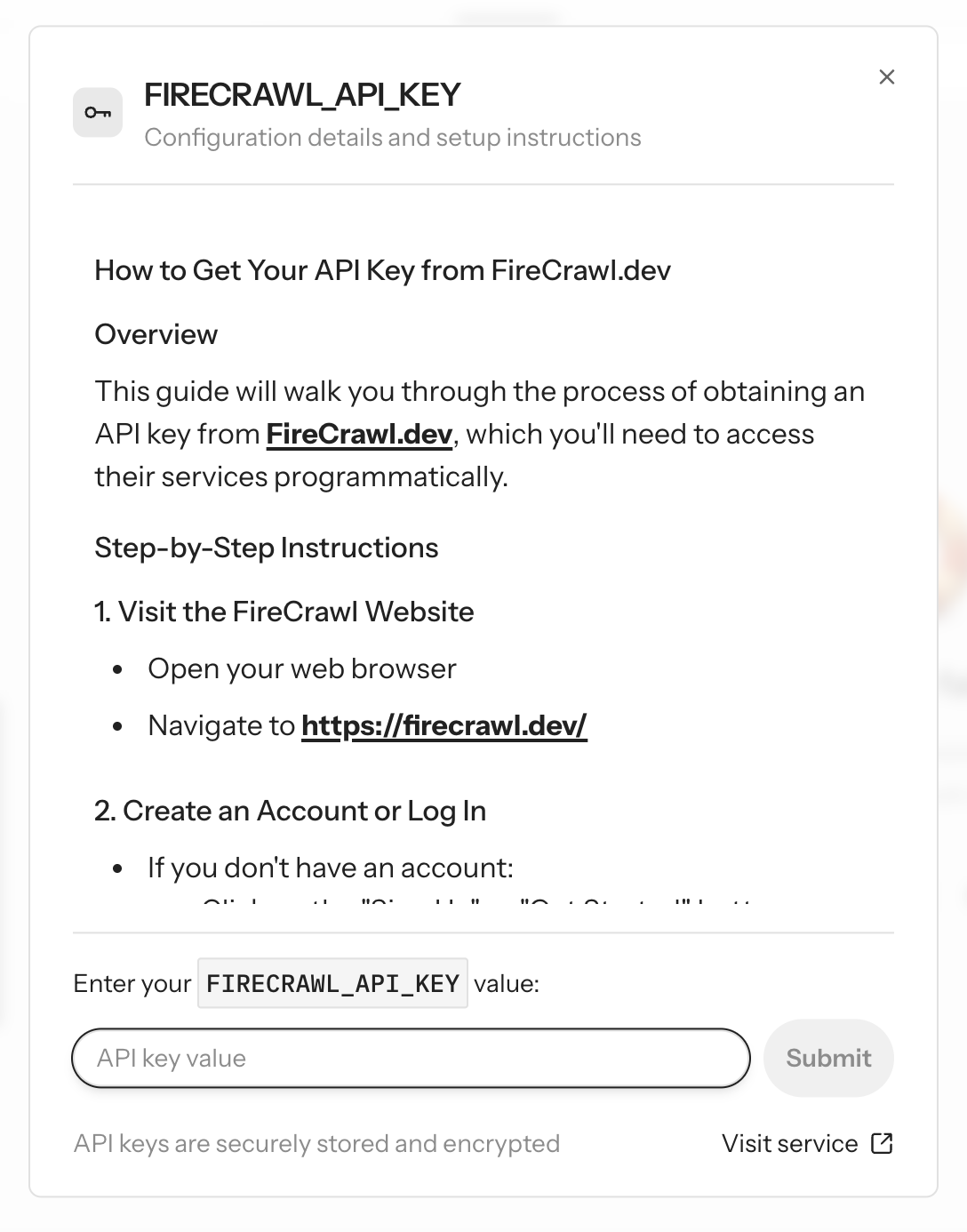
Debugging the Data Crawler
You may find that the data you get from the web crawl doesn’t match what you expected. This is because the web page is not structured in a way that is easy for the AI to understand. This is the point in the build where you need to debug the data being fetched from the web, and work with the AI to get the data you want. Make direct and specific descriptions of what you are doing, what you should be seeing, and what you’re actually seeing instead. Act as a quality assurance engineer, or a data detective, to help Mocha get to the bottom of the issue.Prompt to the AI
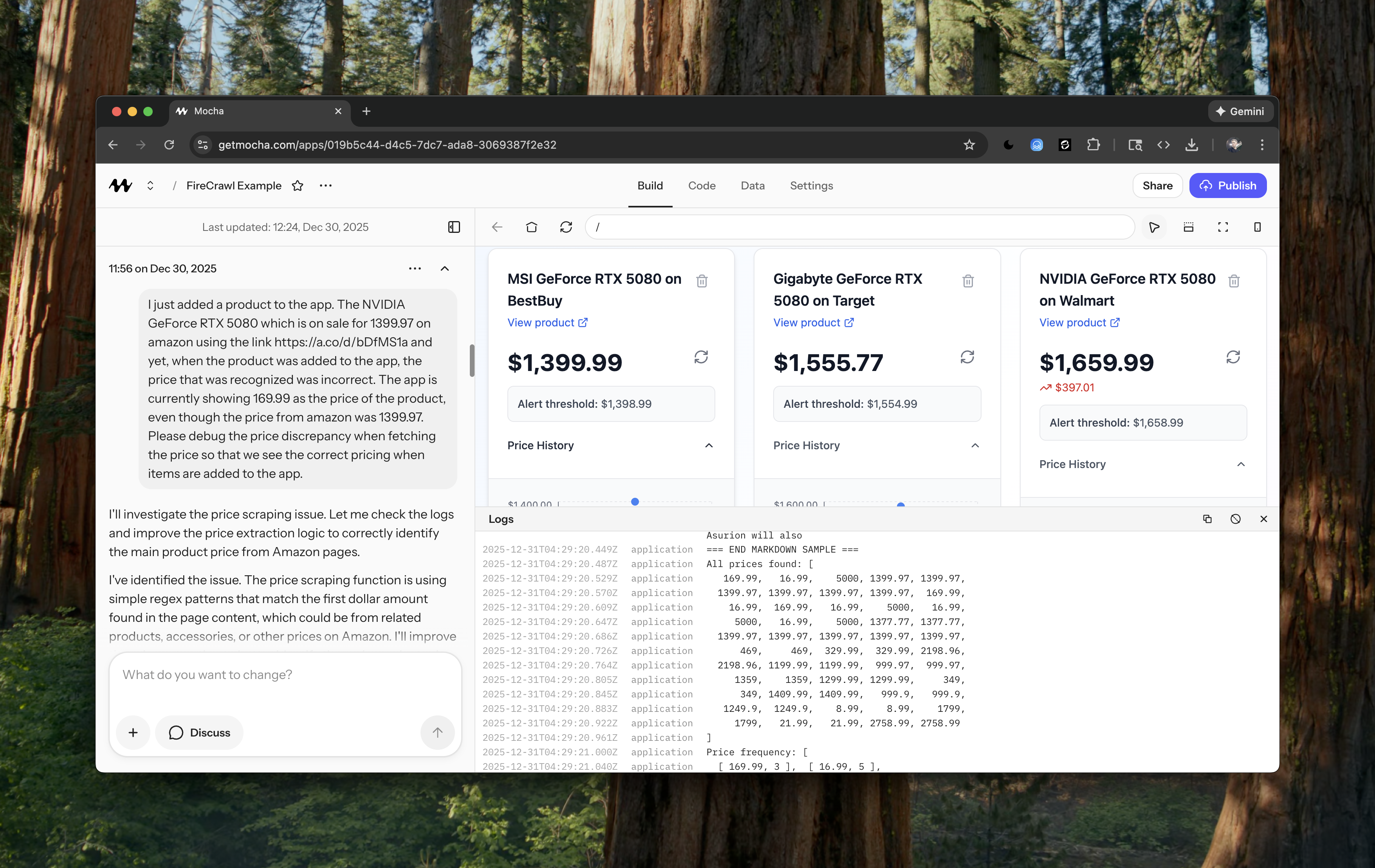
I just added a product to the app. The NVIDIA GeForce RTX 5080 which is on
sale for 1399.97 on amazon using the link https://a.co/d/bDfMS1a and yet, when
the product was added to the app, the price that was recognized was incorrect.
The app is currently showing 169.99 as the price of the product, even though
the price from amazon was 1399.97. Please debug the price discrepancy when
fetching the price so that we see the correct pricing when items are added to
the app.
AI solution to the problem
I’ve updated the price scraping logic with two improvements:
- Better detection: Now looks for specific price labels like “Price:”, “Product Price:”, “Total:”, etc. that Amazon and other retailers use
- Fallback strategy: If no labeled price is found, it takes the highest price on the page (the main product is usually the most expensive item, not accessories or related products)
- Debug logging: Added console logs to help diagnose future issues Debug logging: Added console logs to help diagnose future issues Try adding the product again and it should capture the correct $1399.97 price. The logs will show all prices found and which one was selected.
Prompt to the AI
The total price it is finding now is actually $2,198.96 because it is finding
the “Price:” pattern from the “Total price:” wording present in the
“Frequently Bought Together” section, which adds up 3 items frequently bought
together for a total price to display. We need to nail down the amazon price
scraping feature because amazon is going to be the most common price tracking
source that gets added to this app. We are able to see the actual price of the
item in several places on the page, but I need to know what the response from
Firecrawl looks like so that I can consistently identify the correct price
from the response. A simple pattern matching might work but we have to make
sure it is the correct pattern. I do not see anything in the console when I do
a refresh of the price, which is what I’m using to see the updated price of
the item that I added. Maybe we can add a console log to the refresh action so
that whenever a price is refreshed, we can see what we’re dealing with in the
Firecrawl response.
Describing our solution to the problem
All prices found: [ 169.99, 16.99, 5000, 1399.97, 1399.97, 1399.97, 1399.97, 1399.97, 1399.97, 169.99, 16.99, 169.99, 16.99, 5000, 16.99, 5000, 16.99, 5000, 1377.77, 1377.77, 1399.97, 1399.97, 1399.97, 1399.97, 1399.97, 469, 469, 329.99, 329.99, 2198.96, 2198.96, 1199.99, 1199.99, 999.97, 999.97, 1359, 1359, 1299.99, 1299.99, 349, 349, 1409.99, 1409.99, 999.9, 999.9, 1249.9, 1249.9, 8.99, 8.99, 1799, 1799, 21.99, 21.99, 2758.99, 2758.99 ]Here’s the list of all prices found. Look at how frequently the correct price of 1399.97 appears in there? I think we can use the most frequently appearing price as the price instead of the pattern matching that we’re using today, at least that’s what it looks like will work for amazon links.
Exception for a Walmart link source
All prices found: [ 1659.99, 85, 1399.97, 59, 77, 1399.97, 1262.98, 1262, 1262.98, 150, 1262.98, 1262, 1262.98 ]Walmart link detected - using first price: $1659.99Extracted price: 1659.99
AI solution to the problem
I’ll update the price extraction to use different strategies based on the source. Walmart links will use the first price found, while Amazon and others will continue using the frequency-based approach.Updated the price extraction logic. Now:
- Walmart links use the first price found ($1,659.99)
- Amazon and other sites use frequency analysis (most common price)